





















При перепечатке материалов просим публиковать ссылку на портал Finversia.ru с указанием гиперссылки.
Свидетельство о регистрации СМИ ЭЛ № ФС 77 – 68729 от 17.02.2017

Насколько она хороша?
Вчера Alibaba представила семейство моделей Qwen3, которое по синтетическим бенчмаркам вырываются в группу лидеров, но … не является лидером по совокупности параметров, хотя заявка очень сильная.
Интегрально, Qwen3 конкурирует с Gemini 2.5 flash по соотношению цена/качество/производительность, опережая GPT o3 и o4-mini за счет лучшей доступности, но проигрывая по результативности, если цель состоит в генерации лучшего ответа/решения.
Моделей много, но выделю флагманскую - Qwen3-235B-A22B, которая активирует 22 млрд активных параметров из 235 млрд потенциально доступных, снижая требования к вычислительным ресурсам на 85%, сохраняя качество выходных токенов.
Qwen3 построены на базе архитектуры Mixture-of-Experts (MoE). Что это за зверь? Это подход в машинном обучении, который разделяет модель на специализированные подсети («эксперты»), активируемые динамически для каждого входного запроса. Её ключевая идея - повысить эффективность и качество модели за счёт условных вычислений, когда только часть параметров задействуется для обработки конкретного входа, позволяя генерировать токены быстрее и дешевле без потери качества.
Для понимания эффективности архитектуры, Qwen3-4B (4 млрд параметров!) превосходит Qwen2.5-72B-Instruct в задачах общего понимания, а MoE-версия Qwen3-30B-A3B обходит QwQ-32B, активируя лишь 10% параметров.
Для пользователей это означает возможность развертывания локальных очень мощных и производительных моделей с ограниченными ресурсами, буквально на домашних компах.
• +42% точности в математических бенчмарках (MATH, AIME25)
• +37% эффективности в задачах программирования (LiveCodeBench)
• Поддержку 119 языков против 32 в Qwen2.5.
В сравнении с предыдущей версией и основными конкурентами Qwen3 демонстрирует прорыв в эффективности ресурсопотребления при сохранении лидирующих позиций в математических и кодирующих задачах.
Значительно улучшены возможности в мультимодальности (обработка видео и изображений), заявлена способность поглощать видео длительностью до 1 часа с точностью до секунды, не теряя детали.
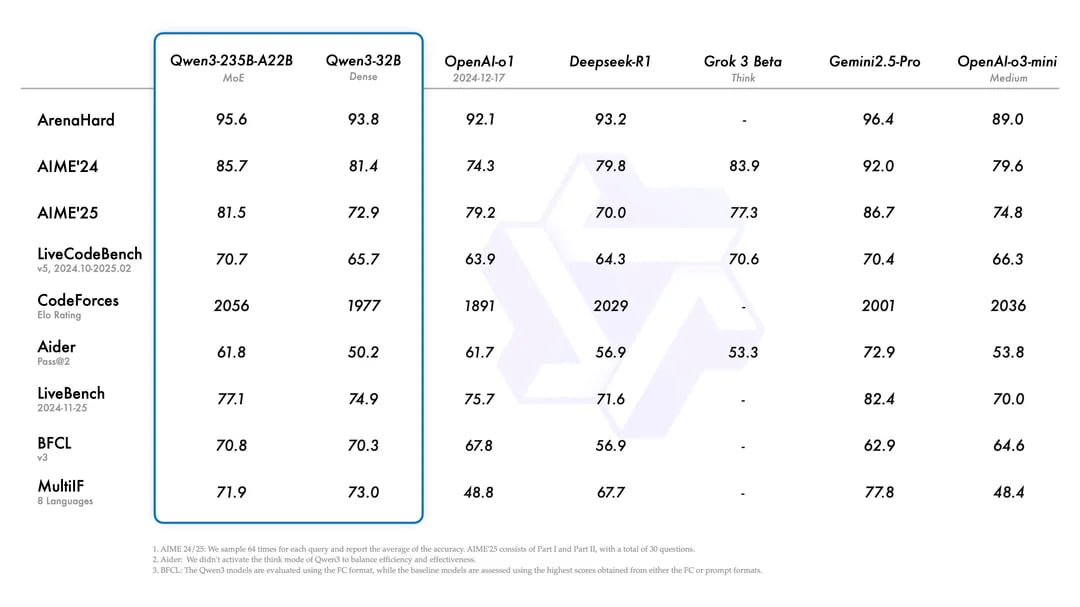
По бенчмаркам выглядит достойно, но не идеально – в группе лучших LLM, но нужно смотреть детали.
Предварительный срез позволяет судить, что сейчас Qwen3-235B-A22B на третьем месте, уступая лучшей LLM в мире – GPT o3 и рядом с ней находящиеся Gemini 2.5 Pro, но выигрывая у Grok 3, и точно впереди DeepSeek R1, которые навел фурора в январе-феврале.
Весьма достойный ответ от китайцев, ждем DeepSeek R2, который должен выйти 15-25 мая. В начале мая Илон Маск обещал представить Grok 3.5. Конкуренция обостряется.
Qwen3 уже доступен бесплатно на официальном сайте.
Telegram канал автора: https://t.me/s/spydell_finance/
В разделе «Обзор блогов» редакция представляет републикации наиболее интересных постов известных российских экономистов, публицистов, финансистов и экспертов, опубликованных на личных каналах и онлайн-ресурсах авторов. Ссылки на эти ресурсы указаны под обзором. Данные републикации не являются подготовленными специально для Finversia.
Ответственность за информацию, высказанные профессиональные и этические оценки, версии и прогнозы остается на авторах блогов.
Орфография и пунктуация авторов блогов сохранена. Перевод иноязычных блогов – авторы блога.
 Банки в 2025 году
Рекордная прибыль на фоне роста проблем.
Банки в 2025 году
Рекордная прибыль на фоне роста проблем.
 Фондовые индексы США завершают построждественскую сессию без существенных изменений
Основные фондовые индексы США в последний час построждественской сессии остаются стабильными, акции балансируют на исторических вершинах.
Фондовые индексы США завершают построждественскую сессию без существенных изменений
Основные фондовые индексы США в последний час построждественской сессии остаются стабильными, акции балансируют на исторических вершинах.
 Евгений Гуревич: «ИИ в страховании жизни – это не хайп, а точка роста»
Генеральный директор компании «Капитал Лайф Страхование Жизни» (КАПИТАЛ LIFE) Евгений Гуревич в интервью «Б.О» обсудил с Павлом Самиевым, генеральным директором АЦ «БизнесДром», ключевые тенденции применения искусственного интеллекта, развитие цифровой медицины и роль инноваций в трансформации страхования жизни.
Евгений Гуревич: «ИИ в страховании жизни – это не хайп, а точка роста»
Генеральный директор компании «Капитал Лайф Страхование Жизни» (КАПИТАЛ LIFE) Евгений Гуревич в интервью «Б.О» обсудил с Павлом Самиевым, генеральным директором АЦ «БизнесДром», ключевые тенденции применения искусственного интеллекта, развитие цифровой медицины и роль инноваций в трансформации страхования жизни.

обсуждение